The law of conservation of coupling
Much has been written about cohesion and coupling in programming, with a general consensus that reducing coupling between modules while increasing cohesion within them is ideal. But what if I told you that decoupling isn’t the silver bullet many coding gurus claim? In practice, it often leads to unnecessary busywork, bloated codebases, more bugs, and reduced performance. Let's take a systems theoretic view because when we build software we build information systems. A system is a whole that is defined by its function in a larger system (or systems) of which it is a part and that consists of at least two essential parts. These parts must satisfy these three conditions.
- each part can affect the behavior of the whole
- no parts have an independent effect on the whole
- every subset of parts can affect the behavior or properties of the whole, and none have an independent effect on the whole When a system is taken apart, it looses all its essential properties, and so do its parts. In software, the system doesn't necessarily loose its properties, but decoupling makes it a lot harder, to fulfill its function.
As a program matures, the more system like it becomes and so called cross cutting concerns dominate. Cleanly separable modules, objects, components or layers are fugazi, they exist only in toy programs that have not met with reality.
The Law of Conservation of Coupling (The Law of Conservation of Self-similarity)
The reason for the two names is that coupling and self similarity are very closely related, if we can see self similarity somewhere, there is also coupling and vice versa. I will explain how later in the blog post.
I want to highlight two main views on a system: the flow view and the structure view.
It seems to me that the the property of coupling or self-similarity is conserved in a system and can move between the structure view and the flow view.
Coupling in flow is almost always worse than coupling in structure.
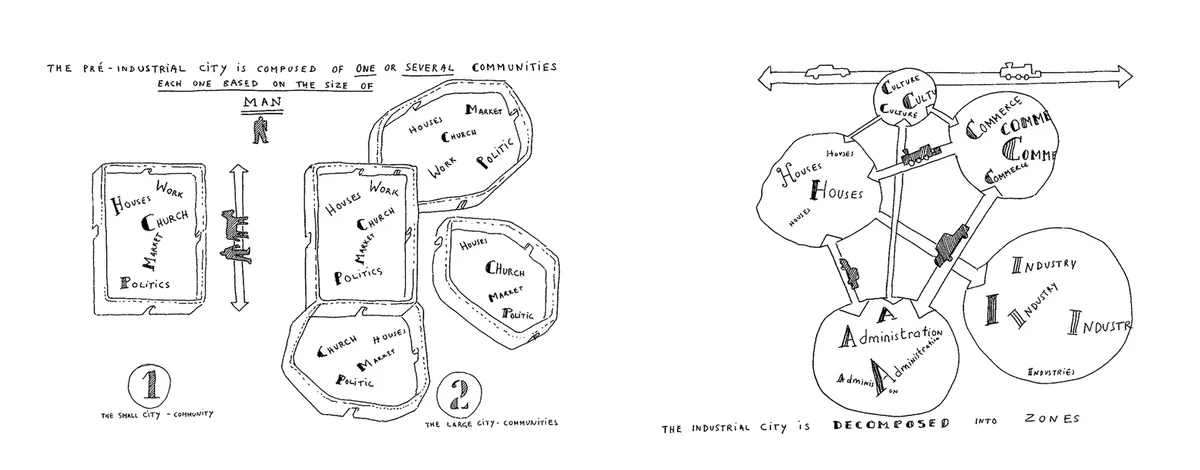 Images are from archdaily.com
Images are from archdaily.com
Let's apply the law to this drawing, it shows two different structures of a city. As you can see in the left image, concerns are coupled, and repeated, each module of the city, serves the concerns of: Houses, Work, Church, Politics, Market. In the right image, concerns are separated, or decoupled into different modules: Houses, Culture, Commerce, Administration, Industry. We can see that going from the left drawing to the right, coupling decreased. Where is the conservation of coupling? Well, it moved into flow. What happens when people are going to work in the morning in the right drawing? Well, roads have a limited bandwidth, so one persons time it takes to get to work, depends on everyone that wants to go from the Houses to Industry, or from Houses to Commerce gets coupled to everyone else, and transit time greatly increases. In essence coupling moved from structure (where people live), to flow (how people travel).
How is coupling related to self-similarity?
You probably heard about self similarity from fractals, where the whole is similar to the parts. If we take the organization point of view. In the left drawing, the whole thing is a city, and the modules can also be considered cities. In the right drawing, the whole thing is a city, but a module is not a city. If we take the flow view and graph the time it takes for people to get where they want to get. It will look similar to a stock market chart The Misbehavior of Markets: A Fractal View of Financial Turbulence - Benoit Mandelbrot. If you live in the city in the drawing to the right, and you go to work when no one is on the roads, you can probably get there in 20 minutes, if you go when everyone else is, you can sit in traffic for hours.
Self similarity of internet traffic
Here is an example regarding internet traffic.
Internet traffic is self-similar. In 1994, a paper was published by a group at Bellcore showing that measurements of Internet traffic on various Ethernets exhibited self-similarity. Some found this a revelation—that this was the first inkling that traffic was not Poisson—when, in fact, this fact had been known since the mid-1970s.25 This observation created huge interest, and a lot of researchers jumped on the bandwagon. There was more than a little infatuation with the idea that the Internet was described by the hot new idea of fractals, chaos, the butterfly effect, etc. Although not reported in that paper, there were immediately deep suspicions that it wasn’t Internet traffic per se or Ethernet traffic that was self-similar, but that the self-similarity was an artifact of TCP congestion control. This was later verified. TCP traffic is more strongly self-similar than UDP traffic, and Web traffic is somewhat less self-similar than TCP traffic. The lower self-similarity of Web traffic is most likely a consequence of the “elephants and mice” phenomenon. But interestingly enough, the result that TCP congestion control was causing chaotic behavior did not precipitate a review of how congestion control was done. The general view of the community seemed to be that this was simply a fact of life. This is in part due to the ideas being currently in vogue and the argument being made by some that large systems all exhibit self-similar behavior, so there is nothing to do. --- Patterns in Network Architecture - John Day page XXV
Papers: On the Self-Similar Nature of Ethernet Traffic ( extended version ) Effect of TCP on self-similarity of network traffic Because of the premature separation of layers, congestion control was basically put in the wrong layer, read John Days book (mentioned above) for more on this.
Here is how we get one layer of burstiness from one kind of separation of concerns namely memory management.
src: https://discord.com/blog/why-discord-is-switching-from-go-to-rust
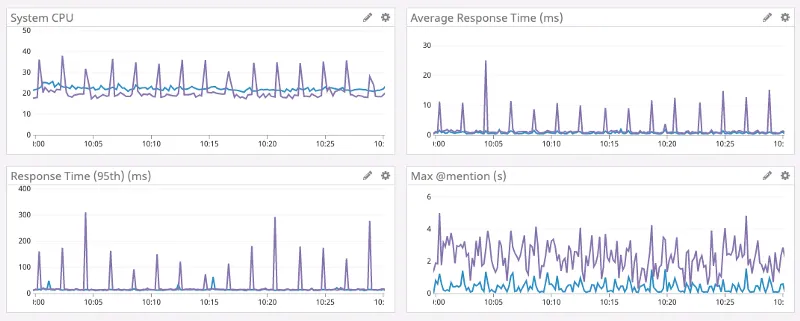 I took the graphs from this article, written by discord engineers, about how they went from the purple graph to the blue graph by porting their code from Go to Rust.
https://discord.com/blog/why-discord-is-switching-from-go-to-rust
As we can see, the resource use or flow graph is bursty in the case of Go and less bursty for Rust.
So when they ported their code, they moved coupling from flow, to organization.
We can see the decrease in coupling in the flow view in the graph.
Where did it increase in the structure view?
In Rust the programmer manually (or semi-manually with help from the compiler) manages memory, in Go however memory is management is decoupled from normal code and handled by a split mind (garbage collector) that communicates with the programmer via an imperfect channel: the source code. Because of this imperfect communication channel and Ashbys law (see Control) it cannot accurately model how memory is used and cannot compensate for perturbations
If the look at the natural variation that comes from the domain or incidental variation in in system CPU it has a range from about
I took the graphs from this article, written by discord engineers, about how they went from the purple graph to the blue graph by porting their code from Go to Rust.
https://discord.com/blog/why-discord-is-switching-from-go-to-rust
As we can see, the resource use or flow graph is bursty in the case of Go and less bursty for Rust.
So when they ported their code, they moved coupling from flow, to organization.
We can see the decrease in coupling in the flow view in the graph.
Where did it increase in the structure view?
In Rust the programmer manually (or semi-manually with help from the compiler) manages memory, in Go however memory is management is decoupled from normal code and handled by a split mind (garbage collector) that communicates with the programmer via an imperfect channel: the source code. Because of this imperfect communication channel and Ashbys law (see Control) it cannot accurately model how memory is used and cannot compensate for perturbations
If the look at the natural variation that comes from the domain or incidental variation in in system CPU it has a range from about 25 - 20 = 5 for Rust in the case of Go however 38 - 15 = 23. It seems that automatic memory management in this case almost increased variation by almost 4x.
What about peak CPU usage? 25 for Rust and 38 for Go, that is about a 40% increase in this case.
You want peak load resource demand to be below hardware resource limits. There are two ways to do this, either increase resources or reduce accidental variation with redesign. In my view reducing accidental variation is a much better strategy, although it is bad for cloud companies
Microservices
Most microservices are decoupled like the drawing on the right, so coupling moves into flow, and we get self-similar data movement, because most actual use cases need more microservices to coordinate. This decoupling also causes emergent phantom traffic like phenomena of which one example is the thundering herd problem
 image source: https://microservices.io/post/architecture/2023/09/19/assemblage-part-3-whats-a-service-architecture.html
Separation of concerns also moves complexity form developers to sysadmins or devops. The Go vs Rust graph is a good example of that, if you don't deal with memory management locally, and just push it out with garbage collection, it causes these emergent effects in the whole system.
There is a good blog post about a related concept from Venkatesh Rao: A Big Little Idea Called Legibility, where he talks about this book Seeing like a State: How Certain Schemes to Improve the Human Condition Have Failed, it is about how increasing legibility has unintended bad consequences in urban design.
It always seems like a good idea during analysis, but inevitably backfires during synthesis.
In urban planning and architecture we get an unlivable city. In software, we get a hard to maintain codebase and slow software.
image source: https://microservices.io/post/architecture/2023/09/19/assemblage-part-3-whats-a-service-architecture.html
Separation of concerns also moves complexity form developers to sysadmins or devops. The Go vs Rust graph is a good example of that, if you don't deal with memory management locally, and just push it out with garbage collection, it causes these emergent effects in the whole system.
There is a good blog post about a related concept from Venkatesh Rao: A Big Little Idea Called Legibility, where he talks about this book Seeing like a State: How Certain Schemes to Improve the Human Condition Have Failed, it is about how increasing legibility has unintended bad consequences in urban design.
It always seems like a good idea during analysis, but inevitably backfires during synthesis.
In urban planning and architecture we get an unlivable city. In software, we get a hard to maintain codebase and slow software.
Separation of concerns in game entity systems
Casey Muratori talks to The Primeagen about why separating concerns is not such a good idea in games here, because most use cases need different concerns, and you inevitably have to bring those concerns together. The more separated they are, the harder it is to bring it together.
Database interface design
Let's try to order some food at a fast food place with the two interfaces: The tables are modeled to illustrate serial dependencies, that is why burgers, fries, sauces, have different tables SQL:
- insert (customer_id) into order values (12) --> order_id: 101
- insert (order_id) into burger values (101) --> burger_id: 102
- insert (order_id, burger_id) into fries values (102) --> fries_id: 103
- insert (order_id, fries_id) into sauce values (103) --> sauce_id: 104
- The point is that if you want want to link rows in SQL, you have to send different commands, the chain of order, burger ,fries, sauce takes at least 4 round trips, you cannot insert a sauce without having a fries_id to link it to. Datomic:
[
[-1 :order/customer 12]
[-2 :burger/order -1]
[-3 :fries/burger -2]
[-4 :sauce/fries -3]
] -->
[
[101 :order/customer 12]
[102 :burger/order 101]
[103 :fries/burger 102]
[104 :sauce/fries 103]
]
In datomics case, you can link entities with temporary ids in one service packet, and independent of the serial chains, you only need one round trip.
Let's look at the interface from the point of view of view of self-similarity in the structure view:
- SQL interface is not self-similar, the database is a collection of tables, a service packet, however only supports creation, update, delete of rows to a single table, the service packet is a subset of the whole database
- with Datomic, the service packet is a list of facts, the database is also a list of facts, not only that, but the service packet can link different entities inside a transaction with temporary ids Let's look at the interface from the point of view of coupling in structure:
- SQL has intent and ability decoupled, the application server has the intent of creating a transaction, and only the database has the ability
- In Datomics case, the application server has the intent, and the ability, to create a whole transaction, because a transaction is just data, and supports temporary ids.
Let's look at self-similarity in flow view:
- With SQL, under load, because the database has to juggle multiple ongoing transactions, we will get a graph that is self-similar
- With Datomic, since the database does not have to juggle multiple ongoing transactions, we will not get a self-similar graph (garbage collection can actually cause that to be self-similar, which is also a kind of decoupling, but that is for another blog post) Let's look at coupling in flow view:
- with SQL, the time it takes for your transaction to complete, is also coupled to other ongoing transactions
- with datomic, it is much less coupled, because it can process transactions one after another, and doesn't have to juggle multiple ones
Business example
Ikea wanted to smooth out the variation in the amount of air it ships. According to this law, it had to move coupling from flow to structure. The same way that datomic moved the ability to create a transaction to the application node. Ikea moved ability to create furniture to the consumer.
Conclusion
The more we try to artificially decouple systems, the more headaches we create.